“Incontrovertible” Science and the #WarOnWomen
Cornell profs defend study showing academic #WarOnMen.

As the American press reports breathlessly on the #WarOnWomen in conjunction with Hillary Clinton’s Presidential Run Version 2.0, two of Professor Jacobson’s colleagues are battling to defend research showing that there may actually be a campus #WarOnMen.
A favorite assertion of campus-level feminist activists is that women in the sciences have a more difficult time achieving jobs, recognition, and tenure than their male counterparts. Cornell University professors Wendy M. Williams and Stephen J. Ceci decided to test that theory, and published a study of faculty hiring preferences showing that women were preferred over identically-qualified men.
A look at the hard data reveals a shocking truth: Women are being offered science positions at colleges and universities at rates higher than their actual presence within the pool of applicants. For example, analysis of the numbers between 2002 and 2004 reveals that 20% of applicants in mathematics were women, but they received 32% of the job offers.
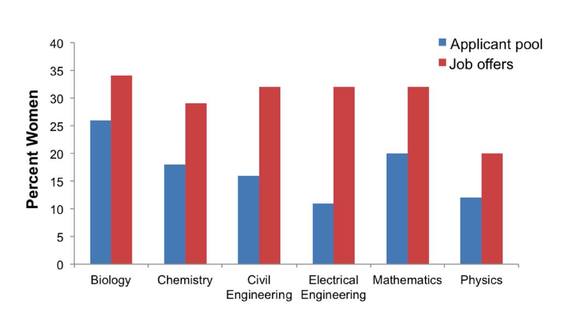
As it was with the other “incontrovertible” science of climate change, the actual result is the opposite from the one predicted by the models; and, as was the case with climate scientists when their data refuted preferred models, the response to the researchers and their report has been exceedingly hostile.
However, Williams and Ceci have soldiered on, countering the numerous attacks on their study.
The bulk of the charges made by academics unhappy with the results focused on the methodology used to obtain the numbers. Williams and Ceci explain why these allegations are patently untrue:
Perhaps the most interesting aspect of this research is that one of the professors’ major goals was to help resolve hiring barriers by determining the root causes of discrimination against women. A careful and unbiased review of their work clearly demonstrates that if the data had shown men were hired preferentially, Williams and Ceci would have detailed that result.
The difference, however, is that their integrity would have remained unquestioned had their results coincided with activist talking points. In all likelihood, both would be receiving numerous scholarly accolades. They would have been the academic equivalent of rock stars.
Instead, both researchers have spent a great deal of time beating back attacks on their work. A favorite claim being used to dismiss their results is that the participants knew that the study was focusing on sexist hiring practices, so the answers obtained were biased to be politically correct.
Williams describes why this charge is completely unsubstantiated.
… First, 30 faculty were asked to guess what the study was about. None guessed correctly. Second, in Experiment 5, faculty were given only a single applicant to rate, male or female. They had no knowledge a mirror applicant was sent to other faculty with the gender changed. Thus, faculty rating the male applicant could not have downgraded him to 7.14 under an assumption that some unknown faculty member elsewhere would upgrade a female applicant to 8.20. Third, if faculty were aware that our purpose was to determine if they are biased, they should have given the same rank to the identically-qualified man and woman (i.e., tie them for first place). Only a handful of faculty chose this option. Fourth, if respondents knew the purpose of the study, why in some conditions was there no female preference? It seems implausible to argue that faculty knew the hypothesis, but only acted upon it occasionally.
In another post, Williams counters the charges that “they studied the wrong question” and that there was “self selection bias” in their study. An unbiased review of the information offered proves these claims are also quite baseless.
…If self-selection was a factor, it would have changed the outcome when the analyses were re-run using sample weights to control for nonresponse. But the results did not change. The irony of this criticism about our alleged failure to check on self-selection is that we went far beyond any previous experiment on gender bias in hiring, by using national-polling-type sample weights to control for response and nonresponse rates in each subgroup of our sample.
It will be fascinating to read their responses to the more ludicrous and politically charged allegations directed at their work: that they are tools of the right wing, their work was not peer-reviewed, they responded only to comments from men, etc. etc. etc.
This is just one more example of the meltdown that occurs when data generated from models is different from the actual numbers generated by reality.
 DONATE
DONATE
Donations tax deductible
to the full extent allowed by law.




Comments
So essentially, how dare they not advance the agenda, regardless of scientific rigor.
“A favorite claim being used to dismiss their results is that the participants knew that the study was focusing on sexist hiring practices, so the answers obtained were biased to be politically correct.”
Delicious irony PLUS self-parody…!!!
WTF is the WHOLE purpose of “political correctness” BUT to mau-mau “correct” behavior out of people…???
See? It’s impossible to satisfy these idiots.
Rags, it’s not only impossible but it’s stupid to even try. The act of trying ADMITS that the premise has value and the only area of dispute is the scope or the depth or the amount of how the premise is made manifest. That it CAN be made manifest is off the table since there is no purpose in arguing over something that CANNOT be made manifest.
Or as someone once said, upon hearing a woman agree that she would have sex for a million dollars, well then dear what would you do for 10 dollars seeing as you have already admitted that you’re a prostitute?
platypus axiom for life: Never accept an adversary’s assertion of how things are. Make him/her prove everything, including the color of the sky.
STOP VETTING ASSERTIONS! YOU’RE KILLING OUR AGENDA!
Henry, shouldn’t you have posted a trigger warning before using all caps? LOL!
OMG, YOU’RE RIGHT! I mean, omg, you’re right. SORRY! I mean, sorry.
http://www.ssa.gov/planners/lifeexpectancy.html
Our beloved Social Security Administration says men reaching 65 have a life expectancy of 84.3 and women 86.6. That of course means you got to 65 in the first place. Think about that 2.3 year gap. If it was the other way around, if men routinely lived longer than women, men would be denied all medical care until the “sexist” life expectancy gap was “corrected”. As it is, women’s longer life expectancy is “natural”, end of discussion. Black men are disproportionately represented in the NBA and for that matter the NFL, end of discussion. Women in science and engineering? Black men in prison? Uh-oh.
And note that both the researchers here, who seem pretty reasonable people, are totally cool with women being favored 2:1 in much of their results.
It never appears to dawn on them how wrong that is if, indeed, they value equality.
Funny, huh?
Funny, yeah. Ha-FREAKIN-ha, lol.
I don’t think it’s natural. I think it’s because males do virtually all the dangerous jobs, and it shows in the overall median number.
I think the difference in lifespan is mostly natural (not caused by differences in accidents, and even that, in the final analysis is natural)
Unless maybe it has soemthing to do with eating patterns.
Or, as a friend of mine who works with Traumatic Brain Injury folks of broad spectrum levels of seriousness related to me his wife’s reaction when he asked her if she’d be surprised to know that most TBIs happen to Guys: “Weeelllll, Duuuhhhh…!!” she replied.
(*His query was whatcha’call “rhetorical”.*)
When a housemate of mine got his PhD in English Lit at Stanford and went out on the job market, he says all the best candidates from Stanford were white men but that the only job offers were for women and one black man. Not a single offer for any of the white men.
Friend of mine in cosmology said the situation was the same in physics. His own work went on to win a Nobel Prize, with the lion’s share of the credit going to senior people who jumped on, while those same senior people promoted a woman of modest talent in the job market, effectively forcing my friend out of the field (after they had stolen his work).
This was in the late 80s and early 90s when many universities were openly declaring that they were only hiring women and minorities. Honestly I’m surprised that this study found anything less than an extreme bias in favor of women. I guess this was just in the assessment phase, looking at how well qualified the men and women were, before deciding how strongly to promote the women ahead of merit.
Well, it makes sense that if they are going to impose an extreme affirmative action boost in favor of women they will want to psychologically justify it by pretending that the women are more meritorious than they are. That is cognitive dissonance 101: people adjust their beliefs to match their actions. They know they are going to favor the woman in the hiring decision so they start right in pretending to themselves that she deserves it.
A high-up studio exec colleague/friend confided to me many years ago that it was(quietly)recognized among his/her kind that, for the “Diversity Police”, a Double Winner was a hire who was Black-Gay…whilst a Triple Winner was a Black-Gay-Female.
At this point it’s on steroids.
Last week I announced in a post that, having learned one may select whatever gender, race, etc., one wants to be, I would henceforth consider myself a female, young, and possibly of Asian descent. I have narrowed my choices. From here on in I am no longer Henry. I am Myoke, a 27 year old young woman from Viti Levu, in the Fiji Islands. Having research young women from the Pacific Islands, I have decided I am also a lesbian.
RESPECT MY CHOICES, or I’ll hound you completely out of your job, home, and place in society.
That’s Pacific Islander, not Asian.
Asians are discriminated against.
http://usatoday30.usatoday.com/news/education/story/2011-12-03/asian-students-college-applications/51620236/1
Sammy, look up the term “concrete” as it applies to cognition.
“Having research[ed] young women from the Pacific Islands, I have decided I am also a lesbian.”
I see what you did there, Henry. I imagine some of them will, too. Dunno about how your Cherokee will feel, but you can try…
Ick-snay on the erokee-Che. Ain’t told her nuthin’ ’bout it yet.
What they don’t want to say is the lower numberds of women in the sciences has something to do with the nature of women or how women live their lives.
It always has to be discrimination, at every stage.
So even when the discrimination is in favor of women, they want to say it’s against them.
Don’t you love the conclusion that the resources being used to get more women into one program, erroneously, should now be used to help other women in other programs, but **NOT** to help men in programs where they are underepresented.
SMH.